ANN assisted TPS on capped alanine dipeptide 1#
In this notebook you will learn:
how to setup an ANN assisted TPS simulation on a simple molecular system
how to transform atomistic input coordinates to the descriptor space in which the ANN learns
This notebook assumes some familiarity with openpathsampling and aimmd, please try the Toy notebooks first.
%matplotlib inline
import os
import aimmd
import torch
import numpy as np
import mdtraj as md
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = 9, 6 # make the figures a bit bigger
import openpathsampling as paths
import openpathsampling.engines.openmm as peng_omm
import simtk.openmm as mm
import simtk.unit as unit
from simtk.openmm import app
from openmmtools.integrators import VVVRIntegrator
# setup logging
# executing this file sets the variable LOGCONFIG, which is a dictionary of logging presets
%run ../resources/logconf.py
cur_dir = os.path.abspath(os.getcwd()) # needed for relative paths to initial TP
# change to the working directory of choice
wdir = '/home/tb/hejung/DATA/aimmd_scratch/SimData_pytorch_ala/'
#wdir = None
if wdir is not None:
if not os.path.isdir(wdir):
os.mkdir(wdir)
os.chdir(wdir)
# setup logging in that directory
import logging.config
logging.config.dictConfig(LOGCONFIG)
initial TP and states#
Generating the initial TP is out of scope of this tutorial, please consult the openpathsampling examples for that.
# load initial TP for ala (generated at high temp, 400K)
# we load the h5py trajectory and define the states from scratch
# for better machine interoperability and smaller footprint in repo
initialTP_md = md.load(os.path.join(cur_dir, 'ala_400K_TP_low_barrier.h5'))
initialTP = peng_omm.trajectory_from_mdtraj(initialTP_md)
template = peng_omm.snapshot_from_pdb(os.path.join(cur_dir, "AD_initial_frame.pdb"))
# define the CVs
psi = paths.MDTrajFunctionCV("psi", md.compute_dihedrals, template.topology, indices=[[6,8,14,16]])
phi = paths.MDTrajFunctionCV("phi", md.compute_dihedrals, template.topology, indices=[[4,6,8,14]])
# define the states
deg = 180.0/np.pi
C_7eq = (paths.PeriodicCVDefinedVolume(phi, lambda_min=-180/deg, lambda_max=0/deg,
period_min=-np.pi, period_max=np.pi) &
paths.PeriodicCVDefinedVolume(psi, lambda_min=120/deg, lambda_max=200/deg,
period_min=-np.pi, period_max=np.pi)
).named("C_7eq")
alpha_R = (paths.PeriodicCVDefinedVolume(phi, -180/deg, 0/deg, -np.pi, np.pi) &
paths.PeriodicCVDefinedVolume(psi, -50/deg, 30/deg, -np.pi, np.pi)).named("alpha_R")
engine setup#
forcefield = app.ForceField('amber99sbildn.xml', 'tip3p.xml')
pdb = app.PDBFile(os.path.join(cur_dir, "AD_initial_frame.pdb"))
system = forcefield.createSystem(pdb.topology,
nonbondedMethod=app.PME,
nonbondedCutoff=1.0*unit.nanometers,
constraints=app.HBonds,
rigidWater=True,
ewaldErrorTolerance=0.0005
)
integrator = VVVRIntegrator(300*unit.kelvin, # T
1.0/unit.picoseconds, # fric
2.0*unit.femtoseconds) # dt
integrator.setConstraintTolerance(0.00001)
engine_options = {
'n_frames_max': 20000,
'nsteps_per_frame': 10,
}
engine = peng_omm.Engine(template.topology,
system,
integrator,
#openmm_properties={'CudaDeviceIndex': '0', 'CudaPrecision': 'single'},
options=engine_options,
)
engine.name = '300K'
Transforming atomistic coordinates to training descriptors: Symmetry functions and internal coordinates#
# The slow part: symmetry functions
# symmerty functions first
cutoff = 0.6 # consider G5 worst case scenarios for cutoff!
# g2_parms are expected to be a list of lists, each sublist needs to contain [eta, r_s]
g2_parms = [[200., 0.1], [200., 0.25], [200., 0.4]]#, [200., 0.55], [200., 0.7], [200., 0.85]]
# g5_parms are also expected to be a list of lists, here each sublist needs to contain
# [eta, r_s, zeta, lambda]
# here we just create the list of [eta, r_s] for G5,
# we add the missing parmeters below since:
# we use the same zetas, which influence the sharpness of the angular peaks, for all G5s at different probing radii
# and we use the same two lambda values [-1, +1], which influence the location of the maximum, i.e. at angle=0 or at angle=\pi
g5_etas_rs = [[120., 0.1],
[120., 0.25],
[120., 0.4],
#[120., 0.55],
#[120., 0.7],
#[120., 0.85]
]
# all zetas for all G5, high zeta means sharp angular resultion
# Note: zeta must be an even number, using these powers of 2 empirically works well
zetas = [
1,
2,
4,
16,
64,
]
# construct g5_parms from previously defined values
# combine every eta, r_s with all zetas and both possible lambda values
g5_parms = [[eta, r_s, zeta, lamb] for (eta, r_s) in g5_etas_rs for zeta in zetas for lamb in [+1., -1.]]
# combine G2 and G5 params into one list to pass to the SF transformation function
g_parms = [g2_parms, g5_parms]
mol_idxs, solv_idxs = aimmd.coords.symmetry.generate_indices(template.topology.mdtraj,
['HOH'],
solvent_atelements=[['O', 'H']],
reactant_selection='not resname HOH')
sf_parms = {'mol_idxs': mol_idxs, 'solv_idxs': solv_idxs, 'g_parms': g_parms,
'cutoff': cutoff, 'n_per_solv': [[1., 2.]], 'rho_solv': [33.]}
sf_transform = paths.MDTrajFunctionCV('sf_transform', aimmd.coords.symmetry.transform, # transform is an alias for sf
template.topology, **sf_parms)
# The fast part: internal coordinates
pairs, triples, quadruples = aimmd.coords.internal.generate_indices(template.topology.mdtraj, source_idx=0)
ic_parms = {'pairs': pairs, 'triples': triples, 'quadruples': quadruples}
ic_transform = paths.MDTrajFunctionCV('ic_transform', aimmd.coords.internal.transform, # transform is an alias for ic
template.topology, **ic_parms)
# set this to True to do the full setup with symmetry functions, will be much slower
# leave it at False and we will not calculate any symmetry functions and train on internal coords only
# setting this to True will increase runtime by a factor of approximately 10 (depending on the choice of symmetry function cutoff)
we_have_time = True
if we_have_time:
# create this little helper function to concatenate the descriptors we are interested in
def transform_func(mdtra, sf_parms, ic_parms):
import mdtraj as md
from aimmd.coords.symmetry import sf
from aimmd.coords.internal import ic
import numpy as np
return np.concatenate([sf(mdtra, **sf_parms),
ic(mdtra, **ic_parms)],
axis=1)
descriptor_transform = paths.MDTrajFunctionCV('descriptor_transform', transform_func,
template.topology,
sf_parms=sf_parms,
ic_parms=ic_parms,
cv_scalarize_numpy_singletons=False).with_diskcache()
else:
# create this little helper function to concatenate the descriptors we are interested in
def transform_func(mdtra, ic_parms):
import mdtraj as md
from aimmd.coords.internal import ic
import numpy as np
return ic(mdtra, **ic_parms)
descriptor_transform = paths.MDTrajFunctionCV('descriptor_transform', transform_func,
template.topology,
ic_parms=ic_parms,
cv_scalarize_numpy_singletons=False).with_diskcache()
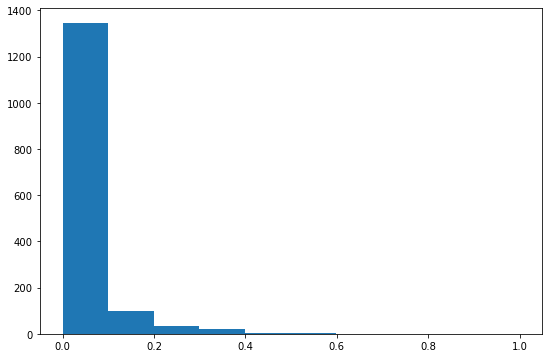
# lets have a look a the transformed coordinate values
# they should be all approximately in [0, 1]
trans_coords = descriptor_transform(template)
# also set cv_ndim, because this will be the number of network inputs
cv_ndim = trans_coords.shape[0]
plt.hist(trans_coords);
aimmd setup: create an ANN, RCModel, etc#
import torch.nn.functional as F
# create a pyramidal feed-forward architecture with a ResNet top part
n_lay_pyramid = 4 # number of layers in the pyramid
n_unit_top = 10 # number of units per layer in the top ResNet part
n_lay_top = 2 # number of ResUnits in the top part, results in n_lay_top * residual_n_skip layers
n_unit_base = descriptor_transform(template).shape[0] # number of inputs to the NN/number of units in the first layer
print('number of input descriptors: ', n_unit_base)
# calculate the factor by which we reduce the number of units per layer in the pyramidal part from layer to layer
fact = (n_unit_top / n_unit_base)**(1./(n_lay_pyramid-1))
ffnet = aimmd.pytorch.networks.FFNet(n_in=cv_ndim,
n_hidden=[max(n_unit_top, int(n_unit_base * fact**i)) for i in range(n_lay_pyramid)], # 4 hidden layer pyramidal network
activation=F.elu,
)
resnet = aimmd.pytorch.networks.ResNet(n_units=n_unit_top, n_blocks=n_lay_top)
torch_model = aimmd.pytorch.networks.ModuleStack(n_out=1, # using a single output we will predict only p_B and use a binomial loss
# we could have also used n_out=n_states to use a multinomial loss and predict all states,
# but this is probably only worthwhile if n_states > 2 as it would increase the number of free parameters in the NN
modules=[ffnet, resnet], # modules is a list of initialized torch.nn.Modules from aimmd.pytorch.networks
)
# move model to GPU if CUDA is available
if torch.cuda.is_available():
torch_model = torch_model.to('cuda')
# choose and initialize an optimizer to train the model
optimizer = torch.optim.Adam(torch_model.parameters(), lr=1e-3)
number of input descriptors: 1507
torch.cuda.is_available()
True
aimmd_store = aimmd.Storage(os.path.join(wdir, 'aimmd_storage.h5'), mode='w')
# we take an ExpectedEfficiencyPytorchRCModel,
# this RCmodel scales the learning rate by the expected efficiency factor (1 - n_TP_true / n_TP_expected)**2
model = aimmd.pytorch.EEScalePytorchRCModel(nnet=torch_model,
optimizer=optimizer,
states=[C_7eq, alpha_R],
ee_params={'lr_0': 1e-3,
'lr_min': 5e-5, # lr_min = lr_0 / 20 is a good choice empirically
'epochs_per_train': 5,
'interval': 5,
'window': 75,
},
descriptor_transform=descriptor_transform,
cache_file=aimmd_store,
)
trainset = aimmd.TrainSet(n_states=2)
trainhook = aimmd.ops.TrainingHook(model, trainset)
storehook = aimmd.ops.AimmdStorageHook(aimmd_store, model, trainset)
densityhook = aimmd.ops.DensityCollectionHook(model)
selector = aimmd.ops.RCModelSelector(model=model,
states=[C_7eq, alpha_R],
distribution='lorentzian',
scale=1.0,
)
OPS setup: TPS strategy and sampled transitions#
network = paths.TPSNetwork.from_states_all_to_all([C_7eq, alpha_R])
move_scheme = paths.MoveScheme(network=network)
beta = 1.0 / (engine.integrator.getTemperature() * unit.BOLTZMANN_CONSTANT_kB)
modifier = paths.RandomVelocities(beta=beta, engine=engine)
tw_strategy = paths.strategies.TwoWayShootingStrategy(modifier=modifier,
selector=selector,
engine=engine,
group='TwoWayShooting')
move_scheme.append(tw_strategy)
move_scheme.append(paths.strategies.OrganizeByMoveGroupStrategy())
move_scheme.build_move_decision_tree()
initial_conditions = move_scheme.initial_conditions_from_trajectories(initialTP)
No missing ensembles.
No extra ensembles.
storage = paths.Storage('ala_low_barrier_SF+IC_pytorch.nc', mode='w', template=template)
sampler = paths.PathSampling(storage=storage,
sample_set=initial_conditions,
move_scheme=move_scheme)
sampler.attach_hook(trainhook)
sampler.attach_hook(storehook)
sampler.attach_hook(densityhook)
sampler.run(2000)
Working on Monte Carlo cycle number 2000
Running for 3 hours 39 minutes 25 seconds - 6.59 seconds per step
Estimated time remaining: 6 seconds
DONE! Completed 2000 Monte Carlo cycles.
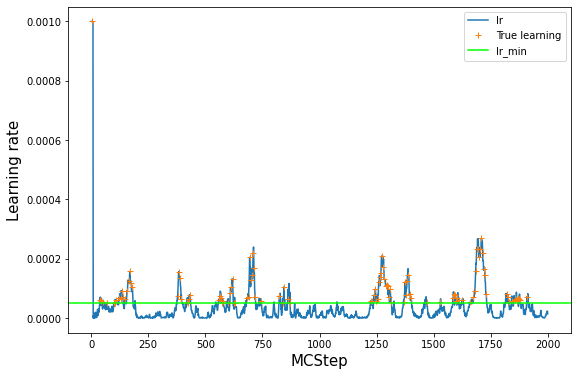
log_train = np.array(model.log_train_decision)
lr = log_train[:,1]
plt.plot(lr, label='lr')
# see where we really trained: everywhere where train=True
# set lr_true to NaN anywhere where we did not train to have a nice plot
lr_true = lr
lr_true[log_train[:,0] == False] = np.nan
plt.plot(lr_true, '+', label='True learning')
# lr_min as a guide to the eye
plt.axhline(model.ee_params['lr_min'], label='lr_min', color='lime')
plt.legend()
plt.xlabel('MCStep', size=15);
plt.ylabel('Learning rate', size=15);
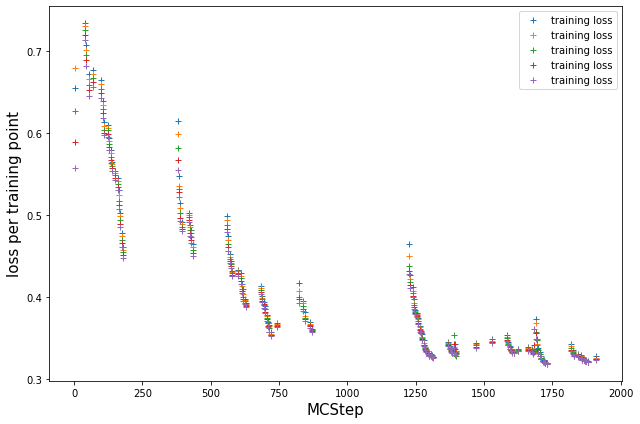
# resort such that we have a loss value per MCStep, NaN if we did not train at that step
train_loss = []
count = 0
for t in log_train[:, 0]:
if t:
train_loss.append(model.log_train_loss[count])
count += 1
else:
train_loss.append([np.nan for _ in range(model.ee_params['epochs_per_train'])])
plt.plot(train_loss, '+', label='training loss')
plt.legend();
plt.ylabel('loss per training point', size=15)
plt.xlabel('MCStep', size=15)
plt.tight_layout()
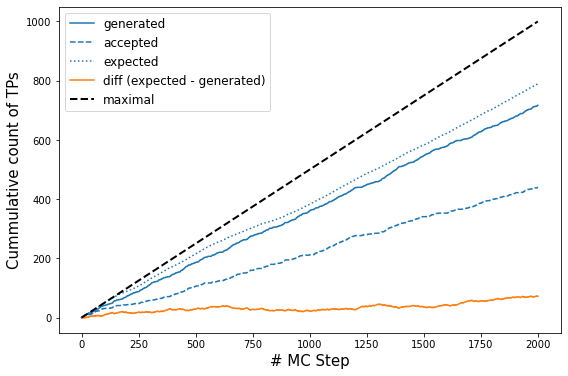
# get the number of accepts from OPS storage
accepts = []
for step in storage.steps:
if step.change.canonical.accepted:
accepts.append(1.)
else:
accepts.append(0.)
p_ex = np.array(model.expected_p)
l, = plt.plot(np.cumsum(trainset.transitions), label='generated');
plt.plot(np.cumsum(accepts), c=l.get_color(), ls='--', label='accepted');
plt.plot(np.cumsum(2*p_ex*(1 - p_ex)),c=l.get_color(), ls=':', label='expected');
plt.plot(np.cumsum(2*p_ex*(1 - p_ex))- np.cumsum(trainset.transitions), label='diff (expected - generated)')
plt.plot(np.linspace(0., len(trainset)/2., len(trainset)), c='k', ls='--', label='maximal', lw=2)
plt.legend(fontsize=12);
plt.ylabel('Cummulative count of TPs', size=15)
plt.xlabel('# MC Step', size=15);
HIPR#
hipr = aimmd.analysis.HIPRanalysis(model, trainset)
hipr_plus_losses, hipr_plus_stds = hipr.do_hipr_plus(25)
loss_diffs = hipr_plus_losses[:-1] - hipr_plus_losses[-1] # hipr_losses[-1] is the reference loss over the unaltered trainset
plt.bar(np.arange(len(loss_diffs)), loss_diffs, yerr=hipr_plus_stds[:-1])
plt.xlabel('Coordinate index', size=15)
plt.ylabel('Relative importance', size=15);
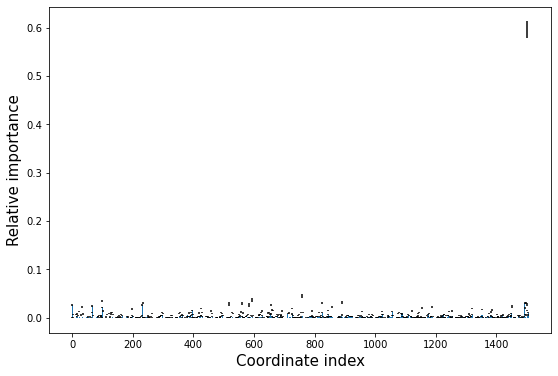
# what are the most important contributors?
max_idxs = np.argsort(loss_diffs)[::-1]
sf_parms = descriptor_transform.kwargs['sf_parms']
ic_parms = descriptor_transform.kwargs['ic_parms']
print('reference loss:', hipr_plus_losses[-1])
for idx in max_idxs[:40]:
print()
print('loss for idx {:d}: '.format(idx), hipr_plus_losses[idx])
print(aimmd.coords.get_involved(idx, sf_parms=sf_parms, ic_parms=ic_parms, solvent_atoms=[['O', 'H']], solvent_resname=['HOH']))
reference loss: 0.3632467651367188
loss for idx 1500: 0.9590144882965089
('SF', ('G5', [120.0, 0.4, 2, -1.0], 21, 'HOH', 'H'))
loss for idx 758: 0.4083429124450684
('SF', ('G5', [120.0, 0.1, 16, -1.0], 21, 'HOH', 'O'))
loss for idx 593: 0.3996204382324219
('SF', ('G5', [120.0, 0.1, 16, -1.0], 16, 'HOH', 'O'))
loss for idx 98: 0.3973171133422852
('SF', ('G5', [120.0, 0.1, 16, -1.0], 1, 'HOH', 'O'))
loss for idx 890: 0.3949944214630128
('SF', ('G5', [120.0, 0.1, 16, -1.0], 3, 'HOH', 'H'))
loss for idx 1493: 0.39363210617065436
('SF', ('G5', [120.0, 0.25, 16, 1.0], 21, 'HOH', 'H'))
loss for idx 1498: 0.3931823140716552
('SF', ('G5', [120.0, 0.4, 1, -1.0], 21, 'HOH', 'H'))
loss for idx 233: 0.39307228401184074
('SF', ('G5', [120.0, 0.25, 1, 1.0], 5, 'HOH', 'O'))
loss for idx 824: 0.39306454734802243
('SF', ('G5', [120.0, 0.1, 16, -1.0], 1, 'HOH', 'H'))
loss for idx 560: 0.3924108724212647
('SF', ('G5', [120.0, 0.1, 16, -1.0], 15, 'HOH', 'O'))
loss for idx 517: 0.3911073852539062
('SF', ('G2', [200.0, 0.1], 14, 'HOH', 'O'))
loss for idx 1501: 0.39014006805419915
('SF', ('G5', [120.0, 0.4, 4, 1.0], 21, 'HOH', 'H'))
loss for idx 583: 0.38994347434997556
('SF', ('G2', [200.0, 0.1], 16, 'HOH', 'O'))
loss for idx 232: 0.38986561683654786
('SF', ('G5', [120.0, 0.1, 64, -1.0], 5, 'HOH', 'O'))
loss for idx 657: 0.389015143737793
('SF', ('G5', [120.0, 0.1, 4, -1.0], 18, 'HOH', 'O'))
loss for idx 1: 0.38901496284484866
('IC', [1, 4])
loss for idx 67: 0.3868617095184327
('SF', ('G5', [120.0, 0.1, 64, -1.0], 0, 'HOH', 'O'))
loss for idx 1451: 0.3855172144317627
('SF', ('G5', [120.0, 0.1, 16, -1.0], 20, 'HOH', 'H'))
loss for idx 857: 0.38538858467102044
('SF', ('G5', [120.0, 0.1, 16, -1.0], 2, 'HOH', 'H'))
loss for idx 32: 0.38455263587951655
('IC', [8, 14, 16])
loss for idx 1187: 0.3843810806274414
('SF', ('G5', [120.0, 0.1, 16, -1.0], 12, 'HOH', 'H'))
loss for idx 100: 0.3841659732055664
('SF', ('G5', [120.0, 0.1, 64, -1.0], 1, 'HOH', 'O'))
loss for idx 1154: 0.38303435478210446
('SF', ('G5', [120.0, 0.1, 16, -1.0], 11, 'HOH', 'H'))
loss for idx 1494: 0.382580640335083
('SF', ('G5', [120.0, 0.25, 16, -1.0], 21, 'HOH', 'H'))
loss for idx 426: 0.38248811836242674
('SF', ('G5', [120.0, 0.1, 4, -1.0], 11, 'HOH', 'O'))
loss for idx 1319: 0.3819457453918457
('SF', ('G5', [120.0, 0.1, 16, -1.0], 16, 'HOH', 'H'))
loss for idx 725: 0.38182475280761724
('SF', ('G5', [120.0, 0.1, 16, -1.0], 20, 'HOH', 'O'))
loss for idx 197: 0.3810885425567627
('SF', ('G5', [120.0, 0.1, 16, -1.0], 4, 'HOH', 'O'))
loss for idx 1352: 0.38021873443603516
('SF', ('G5', [120.0, 0.1, 16, -1.0], 17, 'HOH', 'H'))
loss for idx 1385: 0.3784497678375245
('SF', ('G5', [120.0, 0.1, 16, -1.0], 18, 'HOH', 'H'))
loss for idx 662: 0.37842965339660645
('SF', ('G5', [120.0, 0.25, 1, 1.0], 18, 'HOH', 'O'))
loss for idx 659: 0.37840117805480955
('SF', ('G5', [120.0, 0.1, 16, -1.0], 18, 'HOH', 'O'))
loss for idx 1502: 0.37827670089721677
('SF', ('G5', [120.0, 0.4, 4, -1.0], 21, 'HOH', 'H'))
loss for idx 397: 0.37811344436645505
('SF', ('G5', [120.0, 0.1, 64, -1.0], 10, 'HOH', 'O'))
loss for idx 845: 0.3779867031860352
('SF', ('G5', [120.0, 0.4, 64, 1.0], 1, 'HOH', 'H'))
loss for idx 1121: 0.3773052994537353
('SF', ('G5', [120.0, 0.1, 16, -1.0], 10, 'HOH', 'H'))
loss for idx 791: 0.37707365890502925
('SF', ('G5', [120.0, 0.1, 16, -1.0], 0, 'HOH', 'H'))
loss for idx 459: 0.377033796081543
('SF', ('G5', [120.0, 0.1, 4, -1.0], 12, 'HOH', 'O'))
loss for idx 692: 0.3770057695007325
('SF', ('G5', [120.0, 0.1, 16, -1.0], 19, 'HOH', 'O'))
loss for idx 626: 0.3768632215118408
('SF', ('G5', [120.0, 0.1, 16, -1.0], 17, 'HOH', 'O'))
storage.sync_all()
storage.close()
aimmd_store.close()