Discovering the mechanism of methane clathrate formation#
In this notebook we will apply the aimmd code to existing transition path sampling data of the formation of methane clathrates. The data has originally been generated for the publication “Unbiased atomistic insight in the competing nucleation mechanisms of methane hydrates.” by Arjun, Berendsen and Bolhuis (PNAS September 24 2019; 116(39):19305-19310) https://doi.org/10.1073/pnas.1906502116
The data was generated at four different temperatures T=270 K, T=275 K, T=280 K and T=285 K. Since for this system, the prevalent reaction mechanism changes with temperature, we will train on all temperatures combined and use the temperature as an additional input feature to see if the AI is able to find this change in mechanism.
We will first train a neural network to predict the commitment probabilities for the TPS data, check the accuracy of the prediction using the untrained committor data and then perform a relative input importance analysis to find the most relevant inputs which we will then use as inputs in a susequent symbolic regression run.
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import os
import aimmd
load the data#
We will first normalize the data to lie roughly in [0,1] and then directly put the data into two different aimmd.Trainset, one for training and one for validation.
f = np.load("methane_clathrate_TPS_training_data.npz")
# add temperature as last descriptor
descriptors_tps = [np.concatenate((f["descriptors_270K"], np.full((len(f["descriptors_270K"]), 1), 270)), axis=1),
np.concatenate((f["descriptors_275K"], np.full((len(f["descriptors_275K"]), 1), 275)), axis=1),
np.concatenate((f["descriptors_280K"], np.full((len(f["descriptors_280K"]), 1), 280)), axis=1),
np.concatenate((f["descriptors_285K"], np.full((len(f["descriptors_285K"]), 1), 285)), axis=1),
]
descriptors_tps = np.concatenate(descriptors_tps, axis=0)
shot_results_tps = [f["shot_results_270K"],
f["shot_results_275K"],
f["shot_results_280K"],
f["shot_results_285K"],
]
shot_results_tps = np.concatenate(shot_results_tps, axis=0)
# same for committors/validation data
f = np.load("methane_clathrate_committors_validation_data.npz")
# add temperature as last descriptor
descriptors_committors = [np.concatenate((f["descriptors_270K"], np.full((len(f["descriptors_270K"]), 1), 270)), axis=1),
np.concatenate((f["descriptors_275K"], np.full((len(f["descriptors_275K"]), 1), 275)), axis=1),
np.concatenate((f["descriptors_280K"], np.full((len(f["descriptors_280K"]), 1), 280)), axis=1),
np.concatenate((f["descriptors_285K"], np.full((len(f["descriptors_285K"]), 1), 285)), axis=1),
]
descriptors_committors = np.concatenate(descriptors_committors, axis=0)
shot_results_committors = [f["shot_results_270K"],
f["shot_results_275K"],
f["shot_results_280K"],
f["shot_results_285K"],
]
shot_results_committors = np.concatenate(shot_results_committors, axis=0)
# scale both to lie approximately in [0,1] accodrding to the TPS max/min values
descriptors_tps_scaled = (descriptors_tps - np.min(descriptors_tps, axis=0)) / (np.max(descriptors_tps, axis=0) - np.min(descriptors_tps, axis=0))
descriptors_committors_scaled = (descriptors_committors - np.min(descriptors_tps, axis=0)) / (np.max(descriptors_tps, axis=0) - np.min(descriptors_tps, axis=0))
# and put the data in the trainsets
trainset_tps = aimmd.TrainSet(2, descriptors=descriptors_tps_scaled, shot_results=shot_results_tps)
trainset_committors = aimmd.TrainSet(2, descriptors=descriptors_committors_scaled, shot_results=shot_results_committors)
len(trainset_tps)
3398
Define a (simple) neural network and train it#
We choose a comparably simple pyramidal architecture, because the descriptors are already a high level description of the system (i.e. collective variables designed by experts on the system) and because we have only around 3400 training points to train on.
import torch
import torch.nn.functional as F
n_base = trainset_tps.descriptors.shape[1]
ffnet = aimmd.pytorch.networks.FFNet(n_in=n_base,
n_hidden=[int((n_base) / i) for i in range(1,9)], # 8 hidden layer pyramidal network
activation=F.elu,
)
torch_model = aimmd.pytorch.networks.ModuleStack(n_out=1,
modules=[ffnet],
)
# move model to GPU if CUDA is available
if torch.cuda.is_available():
torch_model = torch_model.to('cuda')
# choose and initialize an optimizer to train the model
# Note that this should be done after moving the model where it should live (e.g. 'cuda')
optimizer = torch.optim.Adam(torch_model.parameters(), lr=1e-3)
# open/create an aimmd.Storage for saving intermediate and final models
aimmd_store = aimmd.Storage('methane_clathrate_trainNN.h5', 'a')
model = aimmd.pytorch.EEScalePytorchRCModel(nnet=torch_model,
optimizer=optimizer,
states=["A", "B"], # need to pass a list of states (with the correct length),
# such that the model know how many commitment probabilities it is supposed to predict
loss=aimmd.pytorch.rcmodel.binomial_loss, # if loss=None it will choose either binomial or multinomial loss,
# depending on the number of model outputs,
# but we could have also passed a custom loss function if we wanted to
cache_file=aimmd_store, # not strictly necessary if we do not do iterative training and density collection
)
# split of test_frac (10%) of the training data as test data, which we will use to stop the training
test_frac = 0.1
val_split = np.zeros(len(trainset_tps), dtype=bool)
train_split = np.ones(len(trainset_tps), dtype=bool)
val_idxs = np.random.choice(np.arange(len(trainset_tps)), size=int(test_frac*len(trainset_tps)), replace=False)
val_split[val_idxs] = True
train_split[val_idxs] = False
# Note that aimmd.TrainSet can be sliced and will return a new aimmd.TrainSet containing only the slice data
trainset_train = trainset_tps[train_split]
trainset_val = trainset_tps[val_split]
# train the model
# stop if we reach either:
max_epochs = 100000 # maximum number of training epochs overall
max_epochs_sans_improvement = 10000 # maximum number of training epochs without a decrease in test loss
batch_size = None # batch_size=None results in batches of the size of the trainset
#batch_size = 250
test_losses = []
test_losses.append(model.test_loss(trainset_val, batch_size=batch_size))
min_loss = test_losses[0]
train_losses = []
train = True
no_decrease = []
i = 0
while train and i <= max_epochs:
train_losses.append(model.train_epoch(trainset_train, batch_size=batch_size))
test_losses.append(model.test_loss(trainset_val, batch_size=batch_size))
if test_losses[-1] <= min_loss:
min_loss = test_losses[-1]
no_decrease = []
aimmd_store.rcmodels["best_model"] = model # always store the model wit hthe best test loss
else:
no_decrease.append(1)
if sum(no_decrease) >= max_epochs_sans_improvement:
train = False
i += 1
fig, axs = plt.subplots()
axs.plot(test_losses, label="test loss")
axs.plot(train_losses, label="train loss")
axs.set_ylabel("Loss value")
axs.set_xlabel("Training epochs")
axs.legend();
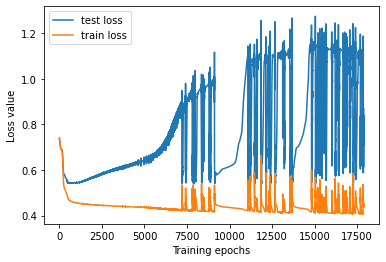
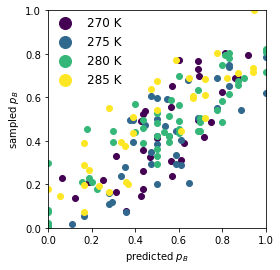
Validation#
Load the model with the best test loss and see how it performs on the untrained committor data. If everything went well all points in the the cross correlation plot should lie on the diagonal.
best_model = aimmd_store.rcmodels["best_model"]
import matplotlib
# NOTE: the colorcoding is for the temperature to spot if the models has trouble with a certain reaction mechanism/specific temperature
fig, axs = plt.subplots()
p_B = trainset_committors.shot_results[:,1] / np.sum(trainset_committors.shot_results, axis=1)
p_B_hat = best_model(trainset_committors.descriptors)
t1_idx = np.where(trainset_committors.descriptors[:, -1] == 0.)[0]
t2_idx = np.where(trainset_committors.descriptors[:, -1] == 1./3.)[0]
t3_idx = np.where(trainset_committors.descriptors[:, -1] == 2./3.)[0]
t4_idx = np.where(trainset_committors.descriptors[:, -1] == 1.)[0]
cmap_obj = matplotlib.cm.get_cmap('viridis')
for idxs, label in zip([t1_idx, t2_idx, t3_idx, t4_idx], ['270 K', '275 K', '280 K', '285 K']):
color = cmap_obj(trainset_committors.descriptors[:,-1][idxs[0]])
axs.scatter(p_B[idxs], p_B_hat[idxs], color=color, label=label)
legend = axs.legend(fontsize=12, loc=(0, 0.63), frameon=False, markerscale=2)
axs.set_aspect('equal')
axs.set_xlim(0,1)
axs.set_xlabel("predicted $p_B$")
axs.set_ylim(0,1)
axs.set_ylabel("sampled $p_B$")
Text(0, 0.5, 'sampled $p_B$')
Relative input importance analysis#
Here we will prepare a trainingset containing all points (committor and TPS data) to perform the relative input importance analysis with the best model. We use all data, because the model is already trained (i.e. no cross contamination possible) and we want the best/most reliable input importances to select the input coordinates to the symbolic regression.
trainset_all = aimmd.TrainSet(n_states=2,
descriptors=np.concatenate([trainset_tps.descriptors, trainset_committors.descriptors], axis=0),
shot_results=np.concatenate([trainset_tps.shot_results, trainset_committors.shot_results], axis=0)
)
hipr = aimmd.analysis.HIPRanalysis(best_model, trainset_all, n_redraw=100)
hipr_plus_mean, hipr_plus_std = hipr.do_hipr_plus()
fig, axs = plt.subplots()
max_idxs = np.argsort(hipr_plus_mean[:-1])[::-1]
axs.bar(np.arange(trainset_all.descriptors.shape[1]), hipr_plus_mean[:-1] - hipr_plus_mean[-1], yerr=hipr_plus_std[:-1]);
axs.set_ylabel("relative input importance")
axs.set_xlabel("coordinate index")
Text(0.5, 0, 'coordinate index')
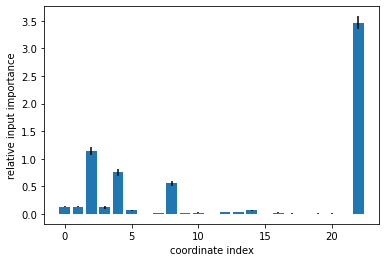
print(max_idxs)
[22 2 4 8 1 0 3 14 5 12 13 10 16 7 9 17 20 19 18 21 6 11 15]
Symbolic regression on the most relevant inputs#
import pyaudi
import sympy as sp
from scipy.special import expit as sigmoid
3 most relevant inputs#
n = 3 # how many of the most relevant coordinates to take
skip = 2 # take only every Nth step to speed up stuff a bit
# create training inputs for symbolic regression
# the training inputs need to be gdual_vdoubles, since we need to be able to calculate gradients w.r.t. them
xt = [pyaudi.gdual_vdouble(trainset_tps.descriptors[::skip, i]) for i in max_idxs[:n]]
# the targets can (and should for efficiency) also be numpy arrays, since we need no gradients for them
yt = trainset_tps.shot_results[::skip]
# always take all points for calculating the test loss
xtf = [pyaudi.gdual_vdouble(trainset_tps.descriptors[:, i]) for i in max_idxs[:n]]
ytf = trainset_tps.shot_results[:]
xt_val = [pyaudi.gdual_vdouble(trainset_committors.descriptors[:, i]) for i in max_idxs[:n]]
yt_val = trainset_committors.shot_results[:]
# initialize symbolic regression expression with random conectivity and random edge weights
expression = aimmd.symreg.initialize_random_expression(n, # n inputs
1, # 1 output: p_B
kernels=['sum', 'diff', 'mul', 'div', 'log', 'exp'], # potentially allowed elementary mathematical operations
# our final expression will be a combination of those operations
# could also add 'sin' and 'sig' for sine and sigmoid
)
# define/choose a loss function and a complexity regularization
lossFX = aimmd.symreg.losses.binom_loss # binmial loss for models predicting p_B in a two state system
complex_fx = lambda ex: aimmd.symreg.losses.operation_count(ex, fact=0.0002) # operation_count counts the number of elementary mathematical operations in the expression
complex_fx_reduced = lambda ex: aimmd.symreg.losses.operation_count(ex, fact=0.00001) # and multiplies it with factor to get a loss contribution
# here we optimize the expression
lossL = []
loss_sans_regulL = []
val_lossL = []
genesL = []
weightsL = []
n_iter = 6 # do it n_iter times in a row to get a feeling for the stability of the result
for _ in range(n_iter):
# initilize a new random expression every time, otherwise we would start the genetic algorithm from the previously optimized individual
# (which would be the same as running one optimization n_iter times longer)
expression = aimmd.symreg.initialize_random_expression(n, 1, kernels=['sum', 'diff', 'mul', 'div', 'log', 'exp'])
loss, genes, weights = aimmd.symreg.optimize_expression(expression, # expression to optimize
4, # number of mutants to create in every generation
300, # maximum number of generations
xt, # training points
yt, # training targets, i.e. shot results
lossFX, # either binomial loss for 2 state (predicting only p_B) or multinomial loss for N state
complexity_regularization=complex_fx, # the combined lambda function(s) we use for complexity regularization
# all of these do not need gradients w.r.t the weights
weight_regularization=None, # combined lambda functions for weight regularizations
# these need and calculate the gradients w.r.t. edge weights
newtonParams={'steps':100}, # newton steps is what makes up most of the runtime,
# however if it is to small expressions will not converge in parameter space
# this can be diagnosed if we have many similar expression with different coeffs
)
# store loss, genes and weights of the best expression found in every round
lossL.append(loss)
genesL.append(genes)
weightsL.append(weights)
# get the loss without regularization on the full dataset, i.e. the negative log-likeliehood (per shoting result)
loss_sans_regulL.append(sum(lossFX(expression, xtf, ytf).constant_cf))
# loss on validation data
val_lossL.append(sum(lossFX(expression, xt_val, yt_val).constant_cf))
/home/tb/hejung/.conda/envs/aimmd_nature_publish/lib/python3.8/site-packages/numpy/linalg/linalg.py:2158: RuntimeWarning: invalid value encountered in det
r = _umath_linalg.det(a, signature=signature)
# print the resulting equations for every round
for vl, ll, l, g, w in zip(val_lossL, loss_sans_regulL, lossL, genesL, weightsL):
# we take a dummy expression and set it to the optimal parameters we found previously
expression.set(g) # set genes to the best we found
expression.set_weights(w) # also set edge weights of the expression
print('loss with regularization on training data: ', l) # this is the loss we had in training, includes all regularizations and is calculated only over the reduced dataset
print('losss without regularization on all data: ', ll) # this is the loss of the expression on the full dataset without regularizations, i.e. log-likeliehood
print("loss without regularization on validation data", vl)
print(expression.simplify(['x{:d}'.format(idx) for idx in max_idxs[:n]], subs_weights=True)) # print the formula, subsitute edge weights to numbers
print()
loss with regularization on training data: 0.4989516661292285
losss without regularization on all data: 0.49191741112863274
loss without regularization on validation data 0.6225222333809788
[24.7463996145995*x2 - 11.9806829332741*x22 + 5.74177695171591*x4 - 2.99641470947613*exp(-2.9421519517725*x22)]
loss with regularization on training data: 0.4993544669386833
losss without regularization on all data: 0.49237460725800797
loss without regularization on validation data 0.6237238079429805
[29.7366645568781*x2 - 11.9041846128731*x22 - 2.88415207168712*exp(-3.21660087112733*x22)]
loss with regularization on training data: 0.49889726911107285
losss without regularization on all data: 0.49105603143485477
loss without regularization on validation data 0.6277801258746839
[x2*(8.65573109153121*x4 + 20.0309807716673) - 9.3237203435571*x22 - 4.04210911235649*exp(-71.5876021703845*x2*x4)]
loss with regularization on training data: 0.4993544669386836
losss without regularization on all data: 0.49237460714067444
loss without regularization on validation data 0.6237238083131724
[29.7366646637679*x2 - 11.9041846355423*x22 - 2.88415207531237*exp(-3.21660077489568*x22)]
loss with regularization on training data: 0.5211623383083411
losss without regularization on all data: 0.512627882126795
loss without regularization on validation data 0.6521128678431284
[x2*(92.422419654588*x4 - 5.67123004031252) - 31.3317831486708*x22*x4]
loss with regularization on training data: 0.4975850728116379
losss without regularization on all data: 0.49035745353107574
loss without regularization on validation data 0.6239675296242247
[27.1482222459119*x2 - 10.9017853518625*x22 - 4.81181204667535*exp(-2.1206641261484*x22 - 5.7575962878567*x4)]
# plot the expression predictions on the validation data
fig, axs = plt.subplots(ncols=n_iter // 2, nrows=2, sharey=True, figsize=(8, 7))
t1_idx = np.where(trainset_committors.descriptors[:, -1] == 0.)[0]
t2_idx = np.where(trainset_committors.descriptors[:, -1] == 1./3.)[0]
t3_idx = np.where(trainset_committors.descriptors[:, -1] == 2./3.)[0]
t4_idx = np.where(trainset_committors.descriptors[:, -1] == 1.)[0]
cmap_obj = matplotlib.cm.get_cmap('viridis')
for axnum, ax in enumerate(axs.flatten()):
p_B = trainset_committors.shot_results[:,1] / np.sum(trainset_committors.shot_results, axis=1)
# set genome and weights in expression
expression.set(genesL[axnum])
expression.set_weights(weightsL[axnum])
# predict p_B
q_B = expression([pyaudi.gdual_vdouble(trainset_committors.descriptors[:, i]) for i in max_idxs[:n]])[0].constant_cf
p_B_hat = sigmoid(q_B)
# plot it, again with color for the temperature
for idxs, label in zip([t1_idx, t2_idx, t3_idx, t4_idx], ['270 K', '275 K', '280 K', '285 K']):
color = cmap_obj(trainset_committors.descriptors[:,-1][idxs[0]])
ax.scatter(p_B[idxs], p_B_hat[idxs], color=color, label=label)
legend = ax.legend(fontsize=10, loc=(0, 0.63), frameon=False, markerscale=2)
ax.set_title(f"loss: {round(val_lossL[axnum], 6)}")
ax.set_aspect('equal')
ax.set_xlim(0,1)
ax.set_xlabel("predicted $p_B$")
ax.set_ylim(0,1)
if axnum == 0:
ax.set_ylabel("sampled $p_B$")
fig.tight_layout()
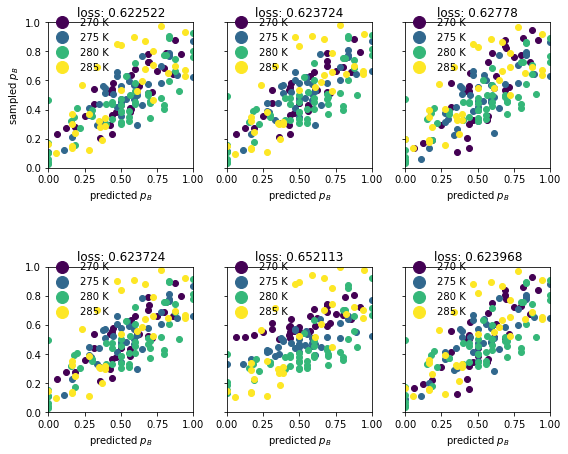
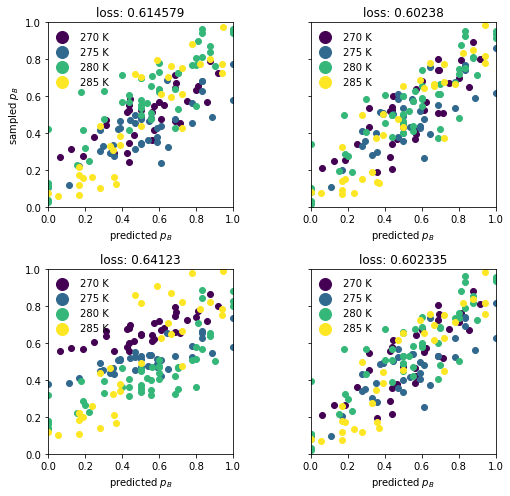
5 most relevant inputs#
n = 5 # how many of the most relevant coordinates to take
skip = 2 # take only every Nth step to speed up stuff a bit
# create training inputs for symbolic regression
# the training inputs need to be gdual_vdoubles, since we need to be able to calculate gradients w.r.t. them
xt = [pyaudi.gdual_vdouble(trainset_tps.descriptors[::skip, i]) for i in max_idxs[:n]]
# the targets can (and should for efficiency) also be numpy arrays, since we need no gradients for them
yt = trainset_tps.shot_results[::skip]
# always take all points for calculating the test loss
xtf = [pyaudi.gdual_vdouble(trainset_tps.descriptors[:, i]) for i in max_idxs[:n]]
ytf = trainset_tps.shot_results[:]
xt_val = [pyaudi.gdual_vdouble(trainset_committors.descriptors[:, i]) for i in max_idxs[:n]]
yt_val = trainset_committors.shot_results[:]
# initialize symbolic regression expression with random conectivity and random edge weights
expression_5in = aimmd.symreg.initialize_random_expression(n, # n inputs
1, # 1 output: p_B
kernels=['sum', 'diff', 'mul', 'div', 'log', 'exp'], # potentially allowed elementary mathematical operations
# our final expression will be a combination of those operations
# could also add 'sin' and 'sig' for sine and sigmoid
)
# define/choose a loss function and a complexity regularization
lossFX = aimmd.symreg.losses.binom_loss # binmial loss for models predicting p_B in a two state system
complex_fx = lambda ex: aimmd.symreg.losses.operation_count(ex, fact=0.0002) # operation_count counts the number of elementary mathematical operations in the expression
complex_fx_reduced = lambda ex: aimmd.symreg.losses.operation_count(ex, fact=0.00001) # and multiplies it with factor to get a loss contribution
# here we optimize the expression
lossL_5in = []
loss_sans_regulL_5in = []
val_lossL_5in = []
genesL_5in = []
weightsL_5in = []
n_iter = 4 # do it n_iter times in a row to get a feeling for the stability of the result
for _ in range(n_iter):
# initilize a new random expression every time, otherwise we would start the genetic algorithm from the previously optimized individual
# (which would be the same as running one optimization n_iter times longer)
expression_5in = aimmd.symreg.initialize_random_expression(n, 1, kernels=['sum', 'diff', 'mul', 'div', 'log', 'exp'])
loss, genes, weights = aimmd.symreg.optimize_expression(expression_5in, # expression to optimize
4, # number of mutants to create in every generation
300, # maximum number of generations
xt, # training points
yt, # training targets, i.e. shot results
lossFX, # either binomial loss for 2 state (predicting only p_B) or multinomial loss for N state
complexity_regularization=complex_fx, # the combined lambda function(s) we use for complexity regularization
# all of these do not need gradients w.r.t the weights
weight_regularization=None, # combined lambda functions for weight regularizations
# these need and calculate the gradients w.r.t. edge weights
newtonParams={'steps':100}, # newton steps is what makes up most of the runtime,
# however if it is to small expressions will not converge in parameter space
# this can be diagnosed if we have many similar expression with different coeffs
)
# store loss, genes and weights of the best expression found in every round
lossL_5in.append(loss)
genesL_5in.append(genes)
weightsL_5in.append(weights)
# get the loss without regularization on the full dataset, i.e. the negative log-likeliehood (per shoting result)
loss_sans_regulL_5in.append(sum(lossFX(expression_5in, xtf, ytf).constant_cf))
# loss on validation data
val_lossL_5in.append(sum(lossFX(expression_5in, xt_val, yt_val).constant_cf))
# print the resulting equations for every round
for vl, ll, l, g, w in zip(val_lossL_5in, loss_sans_regulL_5in, lossL_5in, genesL_5in, weightsL_5in):
# we take a dummy expression and set it to the optimal parameters we found previously
expression_5in.set(g) # set genes to the best we found
expression_5in.set_weights(w) # also set edge weights of the expression
print('loss with regularization on training data: ', l) # this is the loss we had in training, includes all regularizations and is calculated only over the reduced dataset
print('losss without regularization on all data: ', ll) # this is the loss of the expression on the full dataset without regularizations, i.e. log-likeliehood
print("loss without regularization on validation data", vl)
print(expression_5in.simplify(['x{:d}'.format(idx) for idx in max_idxs[:n]], subs_weights=True)) # print the formula, subsitute edge weights to numbers
print()
loss with regularization on training data: 0.4832992715843222
losss without regularization on all data: 0.4802168747886427
loss without regularization on validation data 0.614578592009381
[22.48291674523*x2 + 15.7762126514051*x8 - 2.39672442898549*exp(1.71755944898717*x22)]
loss with regularization on training data: 0.4776321578788419
losss without regularization on all data: 0.47306667620183673
loss without regularization on validation data 0.602379692162284
[-5.56092408880473*x1 + 44.1148215737124*x2 - 3.55547923444299*x8 - 3.33602683201803*exp(1.38577835464871*x2 + 1.3666201575155*x22 - 1.75626878025761*x8)]
loss with regularization on training data: 0.5145525773276722
losss without regularization on all data: 0.5070240894441267
loss without regularization on validation data 0.6412298693753649
[66.6328498085865*x2**2 - 34.5381277200568*x2*x22 + 28.9570994946131*x2*x8]
loss with regularization on training data: 0.4805253247675448
losss without regularization on all data: 0.47395999469753497
loss without regularization on validation data 0.6023347450084946
[x2*(105.124503290922*x8 + 40.427406454404)*exp(-1.25154596171523*x2) - 0.732112503092909*x22*exp(-1.25154596171523*x2) - 11.9412965972981*x8 + 8.64977514118808*x8*exp(-1.25154596171523*x2) - 3.44461688249458*exp(1.42799078762393*x22)]
# plot the expression predictions on the validation data
fig, axs = plt.subplots(ncols=n_iter // 2, nrows=n_iter // 2, sharey=True, figsize=(8, 7))
t1_idx = np.where(trainset_committors.descriptors[:, -1] == 0.)[0]
t2_idx = np.where(trainset_committors.descriptors[:, -1] == 1./3.)[0]
t3_idx = np.where(trainset_committors.descriptors[:, -1] == 2./3.)[0]
t4_idx = np.where(trainset_committors.descriptors[:, -1] == 1.)[0]
cmap_obj = matplotlib.cm.get_cmap('viridis')
for axnum, ax in enumerate(axs.flatten()):
p_B = trainset_committors.shot_results[:,1] / np.sum(trainset_committors.shot_results, axis=1)
# set genome and weights in expression
expression_5in.set(genesL_5in[axnum])
expression_5in.set_weights(weightsL_5in[axnum])
# predict p_B
q_B = expression_5in([pyaudi.gdual_vdouble(trainset_committors.descriptors[:, i]) for i in max_idxs[:n]])[0].constant_cf
p_B_hat = sigmoid(q_B)
# plot it, again with color for the temperature
for idxs, label in zip([t1_idx, t2_idx, t3_idx, t4_idx], ['270 K', '275 K', '280 K', '285 K']):
color = cmap_obj(trainset_committors.descriptors[:,-1][idxs[0]])
ax.scatter(p_B[idxs], p_B_hat[idxs], color=color, label=label)
legend = ax.legend(fontsize=10, loc=(0, 0.63), frameon=False, markerscale=2)
ax.set_title(f"loss: {round(val_lossL_5in[axnum], 6)}")
ax.set_aspect('equal')
ax.set_xlim(0,1)
ax.set_xlabel("predicted $p_B$")
ax.set_ylim(0,1)
if axnum == 0:
ax.set_ylabel("sampled $p_B$")
fig.tight_layout()
aimmd_store.close()